Agentic AI for Customer Journey Intelligence
A major US airline support operation needed to understand what was happening across thousands of customer conversations, not the fraction of 1% a human team could read by hand. We built a batch analysis platform that stitches the full customer journey together from fragmented backend systems, transcribes voice, strips PII, and scores every conversation against the client's own quality rubrics with Claude Sonnet. Leadership now asks questions in plain language and gets same-day answers grounded in 100% of conversations.
Metrics
100%
conversations analyzed, vs under 1% reviewed by hand
2 wks → same day
answers that used to sit in the analyst queue
~85%
agreement with human analyst scoring on the calibration set
100x
analysis throughput, ~2,000 per run vs ~20 a day by hand
Ask a question, get an answer the same day
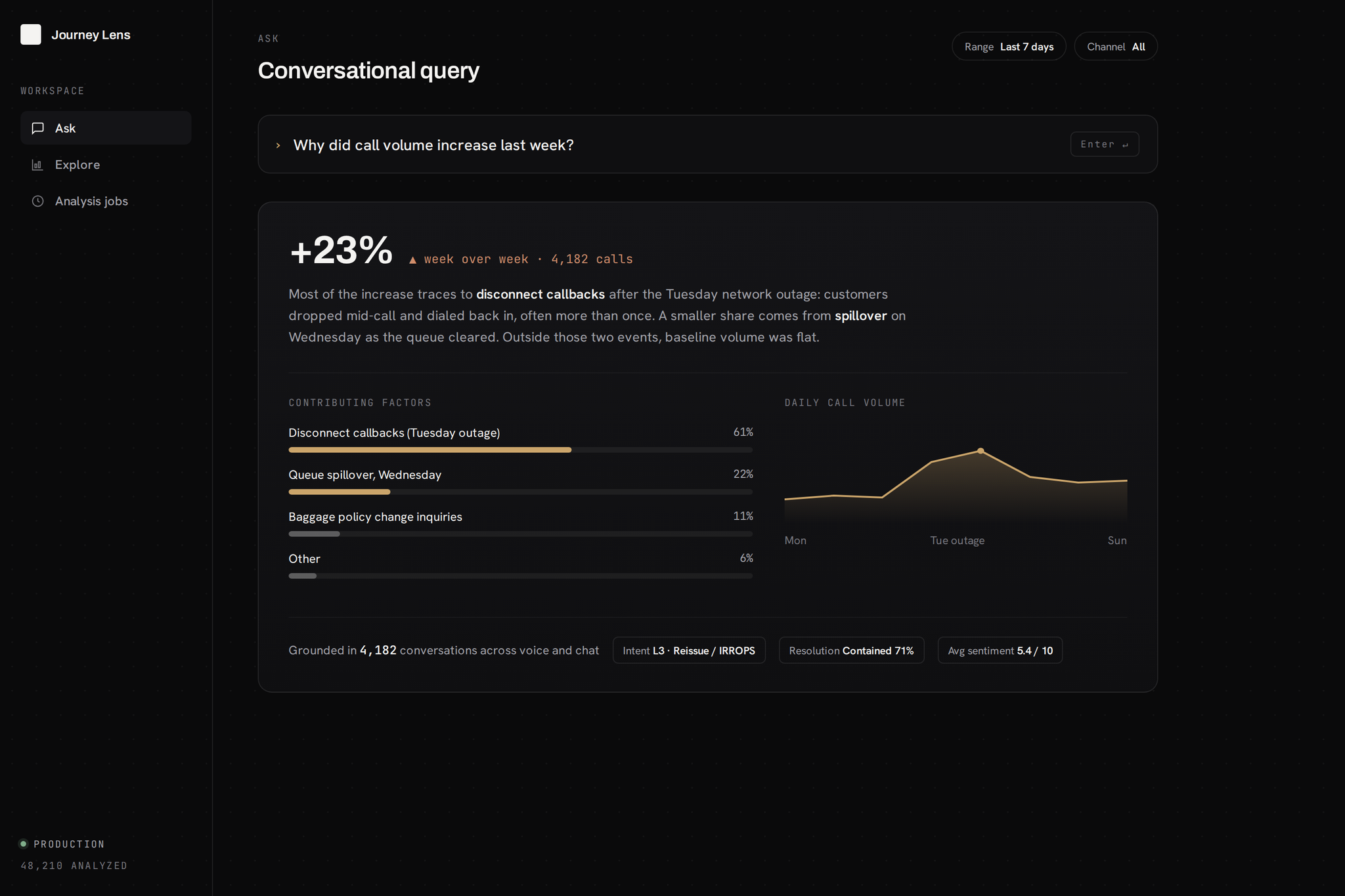
A planning lead asks in plain language: "Why did call volume increase last week?" Same-day answer, grounded in every conversation, not a sample:
"23% increase, driven by disconnect callbacks following the Tuesday outage."
Leadership now sees across 100% of customer conversations, versus under 1% when a human team scored them by hand. Questions that used to sit in an analyst queue for two weeks get answered the same day.
Sector
Customer Experience
Scopes
- Multi-source data stitching
- LLM-as-evaluator
- Batch pipeline architecture
- Conversational query agent
- PII redaction
- AWS cloud architecture
Technologies
- Angular
- TypeScript
- REST API
- JSON / CSV ingest
AWS Services
- Amazon Bedrock
- Amazon Transcribe
- API Gateway
- AWS Lambda
- DynamoDB
- Amazon S3
- CloudFront
Models
- Claude Sonnet
The problem it removes
The data existed but was scattered: chat logs, voice recordings, conversation attributes, routing events, and agent interaction logs in separate systems. No single view of what happened from the moment a customer entered to the moment they left.
Analysts assembled it by hand and got through roughly 20 conversations/day. Reporting ran on tiny samples, insights lagged by weeks, and systemic problems stayed invisible until they became escalations.
The goal: make 100% of conversations answerable in plain language.
How it works
Two phases, and the split is what makes it fast.
Analysis -> scheduled. Backend tables are joined on a common conversation ID (named differently per environment, mapped during integration), voice is transcribed via Amazon Transcribe, and PII is stripped. The reconstructed journey is scored by Claude Sonnet against the client's rubrics.
A run does roughly 2,000 conversations in a few hours.
Answers -> interactive. The dashboard, data explorer, and conversational agent read those pre-analyzed results. The agent searches and synthesizes but never re-runs analysis, so answers come back in seconds.
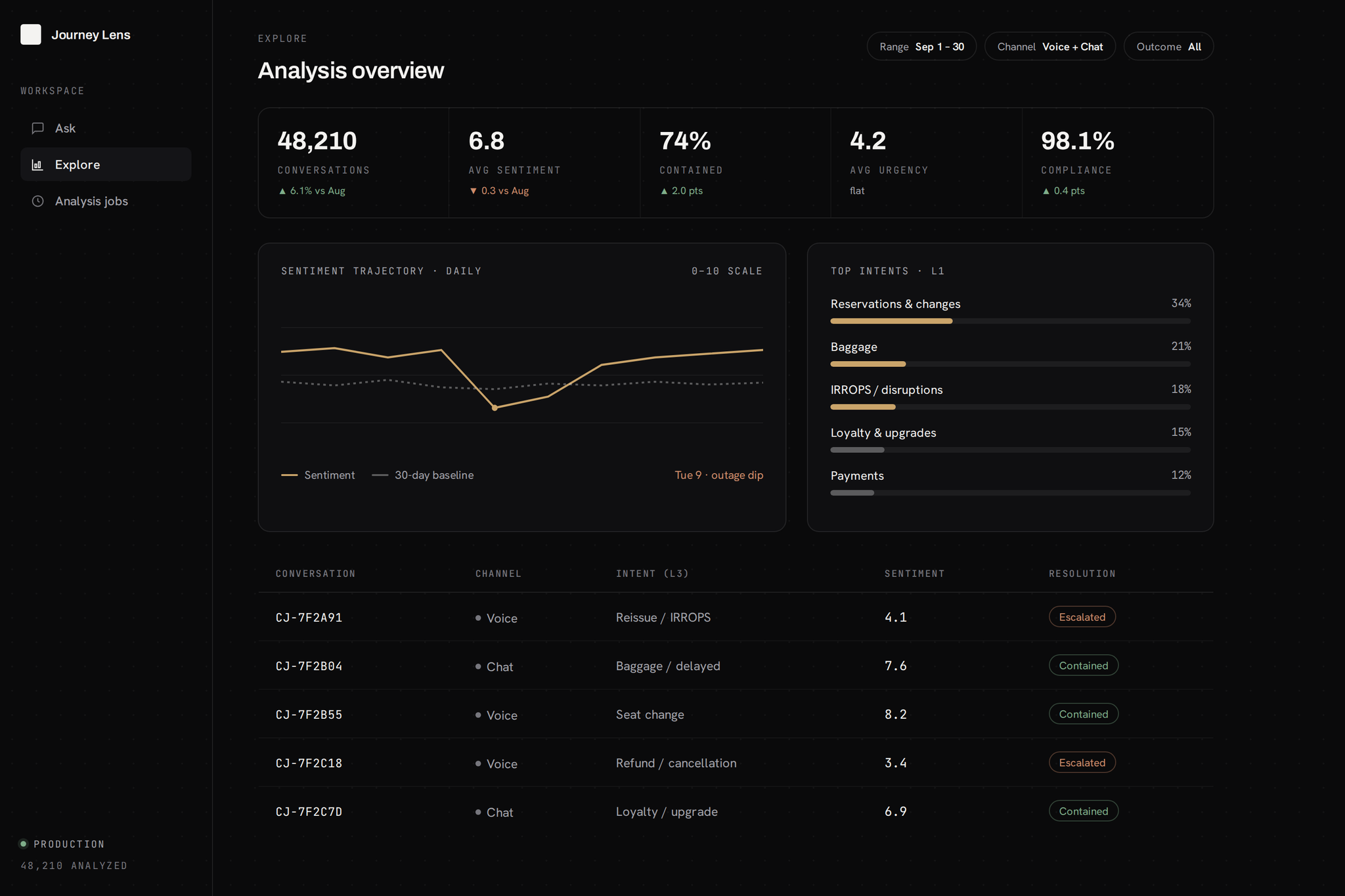
Metrics scored: intent (L1 to L5), sentiment (1 to 10), urgency (1 to 10), resolution (contained or escalated), compliance adherence, specialist performance. All rubric-driven, so the criteria stay in the client's hands.

Can you trust the answer
Model output was compared against conversations the client's analysts had already scored, and the rubrics were refined where they diverged. Exact agreement on the calibration set is ~85%, rising above 90% once scores within one point on the 1-to-10 scales count as matches.
The scores track the client's existing quality framework, not the model's instincts. And because criteria live in a rubric, the client changes them by editing a prompt, not by retraining a model.

Why we built it this way
Why batch, not real-time?
The use cases are reporting, incident investigation, and trend analysis, none of which need per-second latency. Batch keeps compute right-sized and LLM costs predictable, and the job runner scopes each run, a 50-conversation incident dive versus a 2,000-conversation monthly review. Real-time is supported if the need shows up.
Why an LLM evaluator, not a fine-tuned model?
A fine-tuned model bakes evaluation criteria into weights and needs retraining, and fresh training data, every time the rubric changes. Scoring against prompt-encoded rubrics keeps that control in the client's hands. Sonnet was chosen over cheaper models because quality on nuanced criteria (sentiment trajectory across a multi-turn conversation, escalation appropriateness) dropped off sharply with smaller models.
Why strip PII before the model, not after?
Redaction runs on the assembled journey before anything reaches the model. It's deterministic, runs on every conversation, costs zero tokens, and means nothing sensitive ever lands in a prompt or a stored result.
The hard part, stitching the journey
The AI scoring is the visible layer. The harder problem was reconstructing a coherent journey from tables that were never designed to be joined.
The same conversation lives in five places: chat logs, conversation attributes, voice recordings, agent interaction logs, and routing events. Each environment names the shared conversation identifier differently, so the first integration step is finding and mapping that key per environment. Event timestamps don't always line up across systems. Voice and chat logs arrive at different granularity. A normalization layer maps each environment's schema to one unified journey model, ordering every event, message, transfer, hold, and resolution chronologically across channels.
This is the layer everything else depends on. Score a conversation before it's stitched and the model is grading fragments, not the experience. Get the key mapping and the timeline right and the rest of the pipeline (transcription, redaction, scoring, retrieval) has something real to work on.

Dig deeper, how each stage works
🤖 PROGRAMMATIC
Joins fragmented backend tables on a common conversation ID, mapped per environment. Reconciles mismatched ID names, misaligned timestamps, and different granularity between voice and chat into one unified journey model. Without it, everything downstream scores fragments instead of experiences.
"We used to argue about what was happening in our contact center based on the handful of calls someone had time to listen to. Now we ask a question and get an answer grounded in all of it, the same day. It changed what we even think to ask."
Director, Reservations
Why it worked
The win was not the model. It was making every conversation reachable.
By solving journey reconstruction first, and treating Claude Sonnet as a configurable evaluator rather than a fixed black box, the platform turned a two-week sampling exercise into a question you can ask in plain language and answer the same day.
Coverage went from under 1% to 100%. The analyst's job moved from assembling data to acting on it. And because the client owns the rubrics, the system sharpens as the criteria sharpen instead of going stale. Full coverage, fast answers, and client-controlled evaluation is the combination that made it stick.